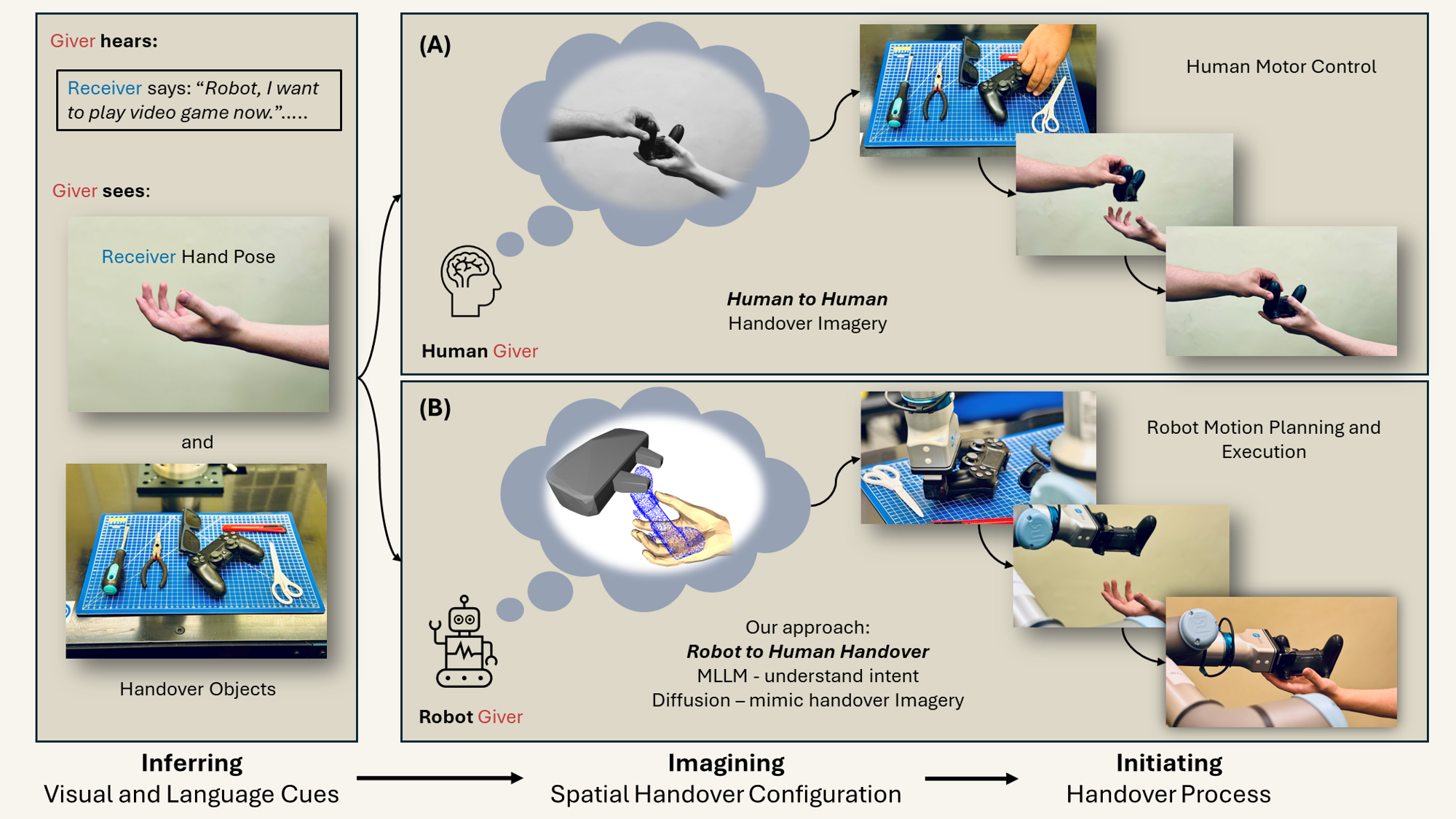
We propose a novel system for robot-to-human object handover that emulates human coworker interactions. Unlike most existing studies that focus primarily on grasping strategies and motion planning, our system focus on 1) inferring human handover intents, 2) imagining spatial handover configuration. The first one integrates multimodal perception—combining visual and verbal cues—to infer human intent. The second one using a diffusion-based model to generate the handover configuration, involving the spacial relationship among robot’s gripper, the object, and the human hand, thereby mimicking the cognitive process of motor imagery. Experimental results demonstrate that our approach effectively interprets human cues and achieves fluent, human-like handovers, offering a promising solution for collaborative robotics.
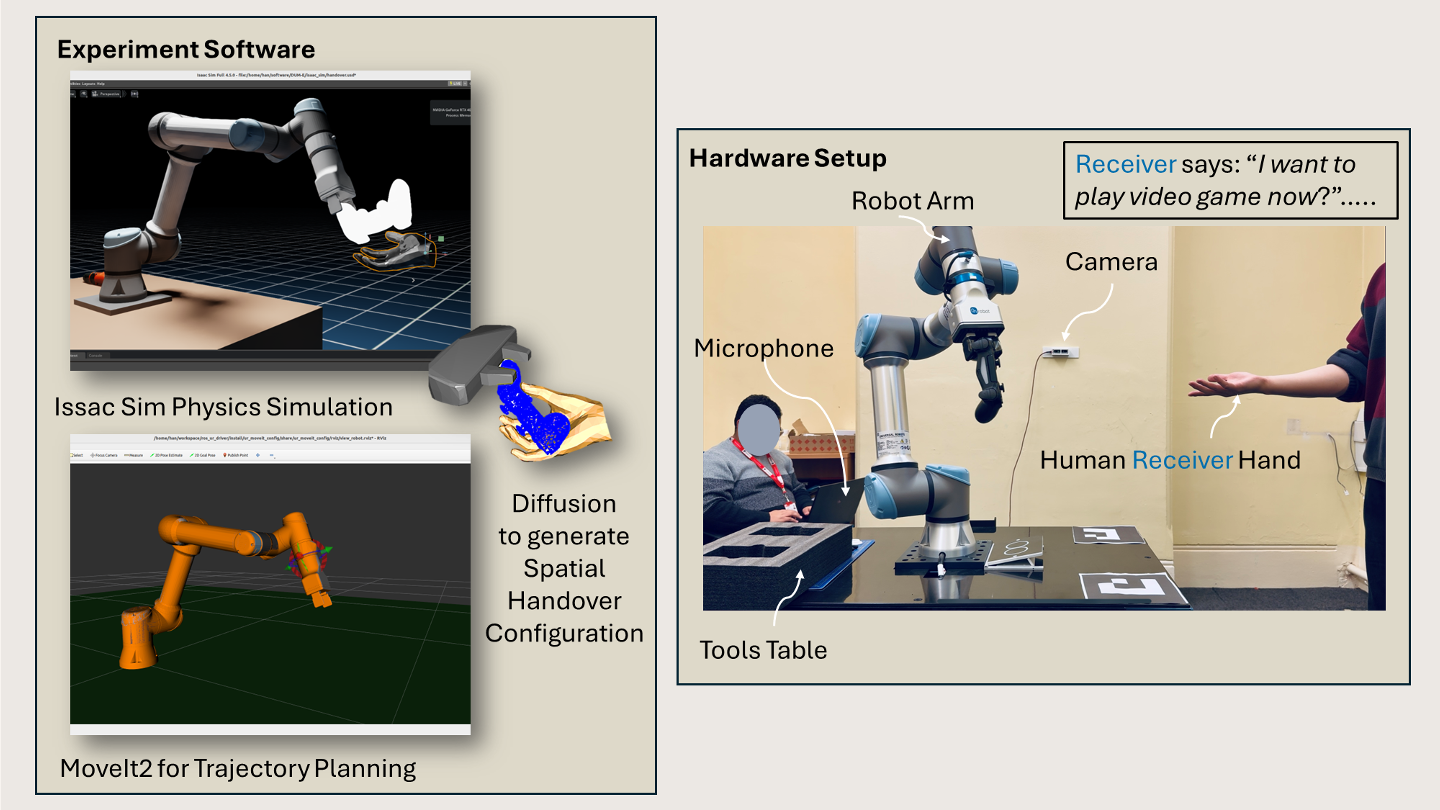
Our method is structured into three key stages: handover intents inferring, handover configuration imagery, and handover pose matching.
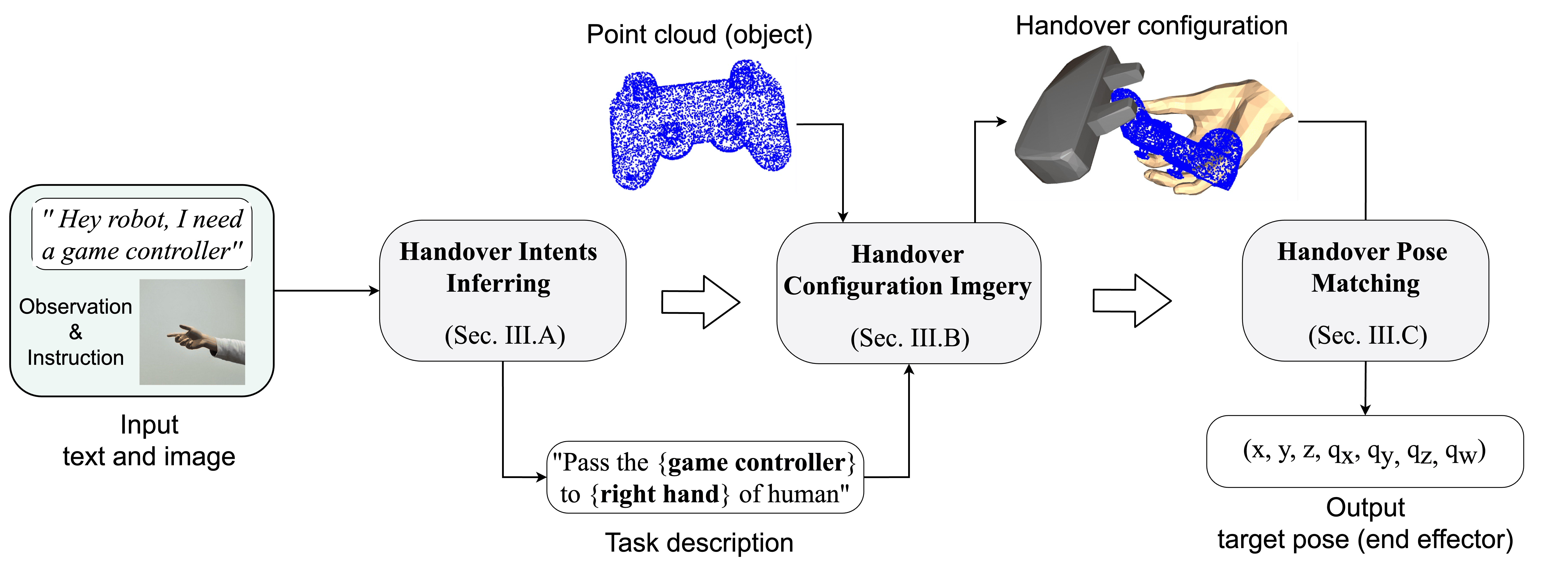
We propose a handover intent recognition method using MLLMs to interpret verbal instructions and visual gestures. Our model processes a text description and an image of the receiving hand to identify the tool and hand type, generating structured outputs like “Pass the game controller to the right hand of the human.”

We introduce a diffusion-based generative model for 3D handover configuration, conditioned on text prompts derived from the recognized intent. This approach enables the generation of spatial relationships among the robotic gripper, the object, and the human hand.
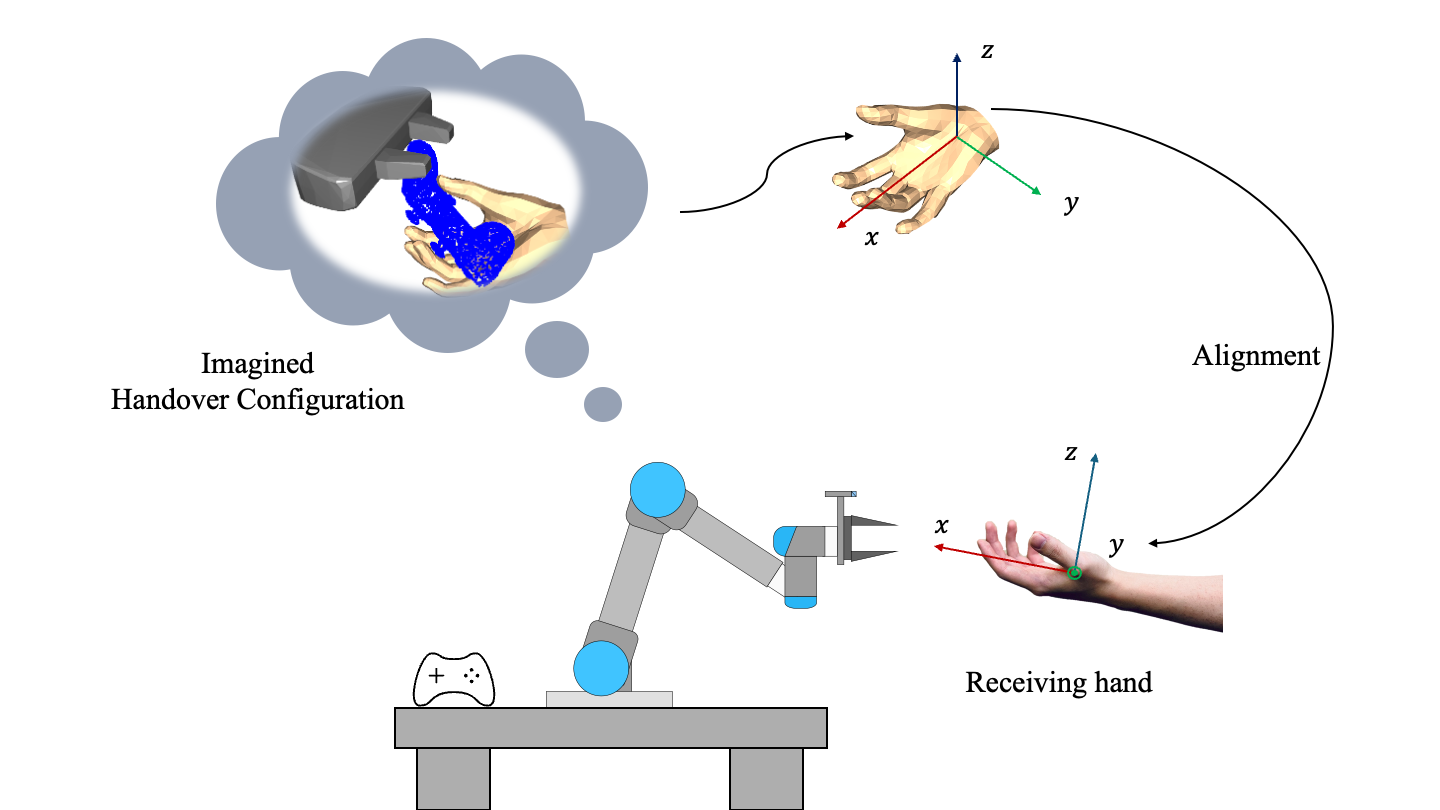
We propose a matching approach to align the generated hand with the real-world hand, preventing contact between the hand and the robotic gripper to ensure the safe handover.
The tests were conducted in both simulation and real hardware. The proposed robotic handover system achieves 80%–93% success rates in real and simulated environments. The total execution time is 9–10 seconds, with 1/3 spent on configuration generation and 2/3 on execution.
We applied the proposed generation method to various daily household items, producing results that define the spatial relationship between the robotic gripper, the object, and the human hand. The following are the visualization results.
@misc{zhang2025generativerobottohumanhandoversintent,
title = {A Generative System for Robot-to-Human Handovers: from Intent Inference to Spatial Configuration Imagery},
author = {Hanxin Zhang, Abdulqader Dhafer, Zhou Daniel Hao, Hongbiao Dong},
year = {2025},
eprint = {2503.03579},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2503.03579},
}